随着电子商务的蓬勃发展和数据量的爆炸式增长,如何从海量数据中挖掘用户偏好、实现精准的商品推荐,并直观地展示分析结果,已成为提升平台竞争力的核心。Python,凭借其丰富的数据科学生态系统,成为开发此类系统的理想选择。本项目旨在构建一个集大数据商品推荐与可视化分析统计于一体的综合系统(代号:2twx0),以赋能商业决策与优化用户体验。
一、 系统核心架构
系统整体采用模块化、分层设计理念,确保可扩展性与可维护性,主要分为三大核心模块:
- 数据层:负责数据的采集、存储与预处理。系统整合来自用户行为日志(点击、浏览、购买、收藏)、商品属性信息、用户画像等多源异构数据。利用Python的
Pandas、NumPy进行数据清洗、转换与特征工程,并使用SQLAlchemy或直接连接HDFS、HBase(针对超大规模数据)或MySQL/PostgreSQL(针对结构化数据)进行数据存储与管理。
- 算法与推荐引擎层:这是系统的“大脑”。基于处理后的数据,实现多种推荐算法:
- 协同过滤:包括基于用户的协同过滤(User-CF)和基于物品的协同过滤(Item-CF),使用
scikit-surprise或TensorFlow/PyTorch实现。
- 内容推荐:利用商品标签、描述文本(通过
Jieba分词、TF-IDF或词嵌入)计算相似度。
- 混合推荐:融合协同过滤、内容推荐以及基于深度学习的模型(如Wide & Deep、Neural CF),以提升推荐的准确性和多样性。该层通过
Flask或FastAPI框架封装为RESTful API服务,供上层应用调用。
- 可视化与分析展示层:这是系统的“仪表盘”。利用强大的Python可视化库,将数据洞察和推荐效果以直观图表形式呈现:
- 用户交互界面:可考虑使用
Streamlit、Dash或Gradio快速构建交互式Web应用,降低开发门槛。
- 统计图表:使用
Matplotlib、Seaborn绘制用户活跃度趋势、商品销量排行、品类分布等统计图表。
- 高级可视化:使用
Plotly、PyEcharts创建可交互的热力图(展示用户-商品关联)、关系网络图(展示商品关联规则)、地理信息图等。
- 推荐结果解释:可视化展示推荐给特定用户的商品列表,并可关联显示推荐理由(如“因为您购买过X”、“与您喜好相似的用户也喜欢”)。
二、 关键技术实现
- 大数据处理:对于实时性要求高的场景,可以集成
Spark(通过PySpark)进行分布式实时计算;对于批处理任务,可使用Apache Airflow进行工作流调度。 - 模型训练与更新:推荐模型需要定期(如每日)使用新数据重新训练以保持时效性。此过程可自动化,并将新模型部署到推荐引擎。
- 系统性能:引入缓存机制(如
Redis)存储热门推荐结果和用户会话数据,以大幅降低数据库压力和API响应延迟。 - 评估与优化:通过A/B测试框架,对比不同推荐策略的效果。关键评估指标包括点击率(CTR)、转化率、准确率、召回率、覆盖率等,这些指标同样应在可视化面板中动态展示。
三、 可视化分析统计功能详述
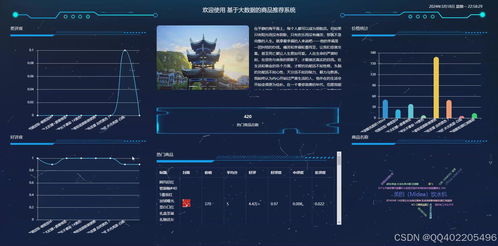
系统可视化面板(2twx0)应包含但不限于以下仪表板:
- 全局概览仪表板:展示核心KPI,如当日总访问量、订单数、推荐点击率、GMV等。
- 用户行为分析板:分析用户生命周期、新老用户占比、活跃时段热力图、用户流失预警。
- 商品分析板:展示商品销量/浏览量的Top N排行、商品品类销售漏斗、库存与销售关联分析。
- 推荐效果分析板:这是系统的特色,可视化展示不同推荐算法的实时效果对比、推荐商品的曝光-点击-转化漏斗、长尾商品覆盖率变化等。
- 个性化查询面板:允许运营人员输入特定用户ID或商品ID,查看该用户的个性化推荐列表及其生成路径,或查看某商品的关联推荐网络。
四、 开发与部署
采用敏捷开发模式,使用Git进行版本控制。环境依赖通过conda或pipenv管理。最终系统可通过Docker容器化,并使用Nginx + Gunicorn部署Web服务,实现高并发访问。整个数据处理与模型训练流水线可部署在云服务器或大数据平台上。
五、
本“基于大数据的商品推荐与可视化分析统计系统”利用Python的全栈数据科学能力,构建了一个从底层数据处理、智能算法推荐到顶层可视化交互的完整闭环。它不仅能够通过精准推荐提升用户满意度和商业收益,更能通过强大的可视化分析功能,将数据转化为直观洞察,为商品运营、市场营销和战略决策提供强有力的数据支撑。系统代号2twx0寓意着通过技术与数据(2进制、twist交织、visualization可视化、analytics分析)实现商业价值的无限(0为循环)探索。